Oct 7, 2024
Speech-to-Speech MT
Real-time speech-to-speech translation presents significant technical challenges due to the computational intensity of the machine learning models involved. These models require substantial resources to process speech rapidly and deliver translations with minimal delay, all while maintaining high accuracy. Constructing an efficient and cost-effective pipeline for this purpose is a complex task.
OpenAI has recently introduced the Realtime API, offering a novel approach to speech-to-speech translation. Traditionally, this process involves transcribing audio using an Automatic Speech Recognition (ASR) model, translating the text via a language model, and then synthesizing the output using a Text-to-Speech (TTS) model. The Realtime API streams audio inputs and outputs directly, reducing latency and preserving nuances such as emotion, emphasis, and accents.
Jump into our GitHub repo to learn more,
https://github.com/pandita-ai/s2s
Objective
Build an efficient and fast Speech-to-Speech Machine Translation model. To do this, we want to use a fast inference API to significantly speed up token generation.
Workflow
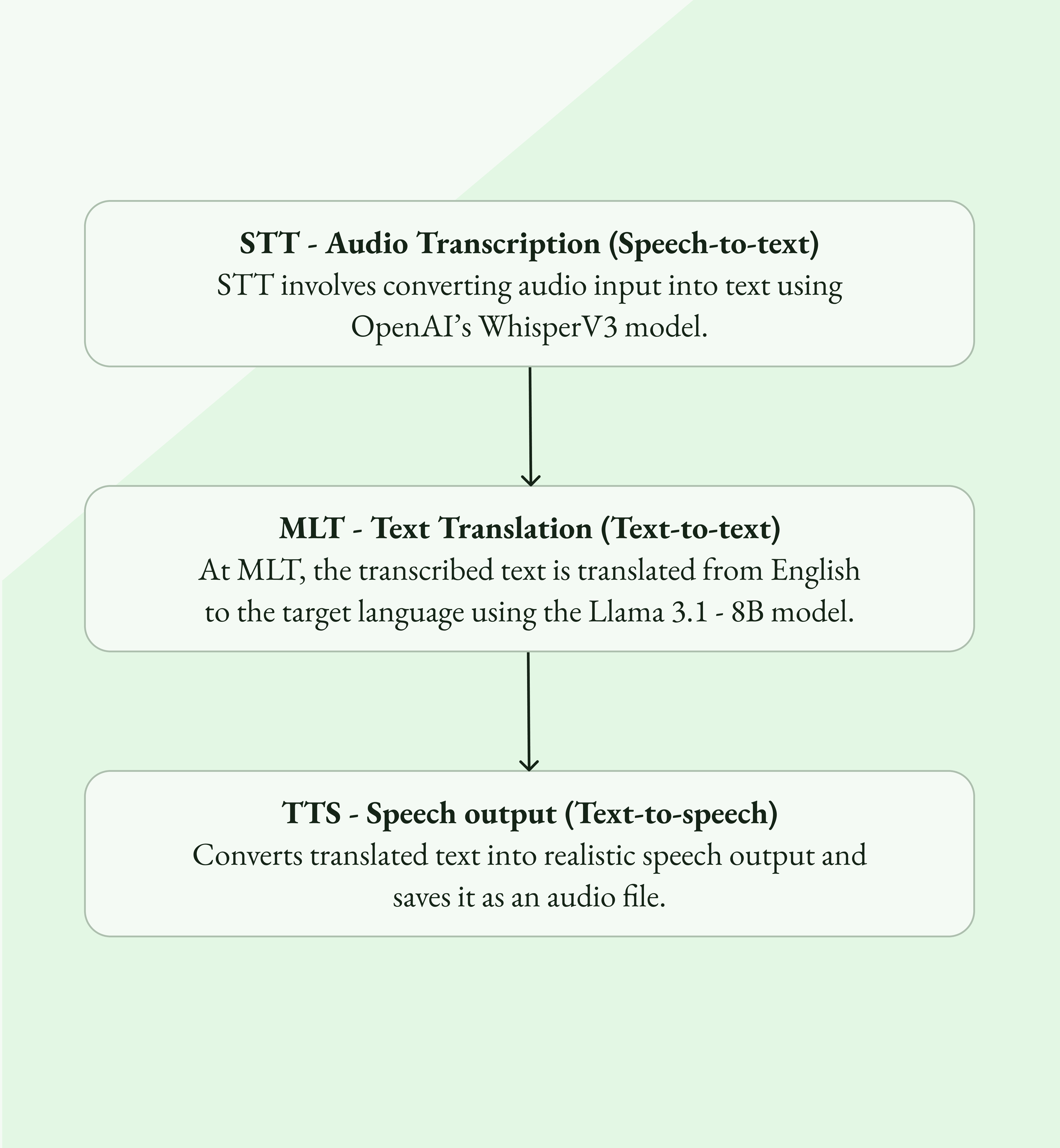
Our approach comprises of these main components,
STT - Audio Transcription (Speech-to-text)
We use OpenAI’s WhisperV3 model for multilingual text transcription from the source language to English. WhisperV3 is a state-of-the-art, open-source model by OpenAI capable of handling a wide array of languages and accents, and it demonstrates robustness against noise and choppy audio.
Audio input can be provided via file upload or recording through a microphone.
Here, we use the Groq API:
MT - Text Translation (Text-to-text)
We utilize Llama 3.1-8B-instant through GroqCloud to translate the transcribed text from English to the target language.
We have used Llama 3.1 for its superior multilingual capabilities and extensive language support compared to other Groq-compatible language models, making it well-suited for translation tasks. Here too we use the Groq API:
TTS - Speech output (Text-to-speech)
OpenAI’s TTS1 model converts the translated text into realistic speech output.
The synthesized speech audio is then saved as a file for playback.
We use the OpenAi API for text-to-speech:
Technology
Our application leverages cloud APIs and Gradio to facilitate the translation process.
OpenAI API
The OpenAI API provides access to powerful and versatile language models, enabling the integration of advanced natural language processing (NLP) functionalities into various applications. Key advantages include:
State-of-the-Art Language Models
Models like GPT-4 offer cutting-edge performance in generating human-like text, understanding context, and handling diverse tasks such as summarization and translation.
The API supports a broad spectrum of tasks, including text generation, conversational agents, summarization, translation, sentiment analysis, content moderation, and more.
Its versatility allows businesses across healthcare, education, finance, and creative industries to leverage the API effectively.
Pre-trained models are ready for use without the need for extensive datasets or specialized training. For domain-specific requirements, the API supports fine-tuning to adapt models for custom needs in legal, medical, or technical fields.
The models excel in producing coherent, fluent, and contextually aware text, enhancing the quality of customer interactions, content generation, and creative writing.
Multilingual capabilities enable processing and generating text in multiple languages, facilitating global applications and overcoming language barriers.
For applications involving private datasets or sensitive information, we don’t recommend OpenAI’s API. Instead, we recommend using custom architecture. That is something our team at Pandita.ai can help with. Contact us at info@pandita.ai for tailored solutions. Our team has extensive experience in handling sensitive data, implementing robust encryption protocols, and creating private deployments that safeguard your information.
Groq Cloud API
The GroqCloud API is unmatched in speed, low latency, and energy efficiency in AI inference tasks and is powered by Groq’s innovative Tensor Streaming Processor (TSP) architecture. This architecture is designed for high-performance, deterministic AI inference, making it ideal for applications requiring rapid processing and high throughput.
Let’s explore some of it’s strengths:
Unrivaled Inference Speed
Leveraging the Groq chip’s single-cycle execution architecture, the API delivers exceptional speeds in AI inference tasks. This is particularly valuable for real-time applications like autonomous driving, financial trading, and robotics. and other time-sensitive tasks.
Deterministic execution ensures that task completion times are fixed and predictable, which is crucial for mission-critical applications where consistent performance is essential, such as in medical diagnostics or aerospace.

The API allows for seamless scaling of AI inference workloads, and Groq’s linear scaling capabilities ensure that adding more processes directly enhances performance without introducing bottlenecks.
Low Latency
Groq’s architecture is specifically designed to minimize latency, making it suitable for applications that require immediate responses, such as real-time video processing, high-frequency trading, and industrial automation.
Energy Efficiency
The TSP architecture’s efficiency results in lower power consumption while maintaining high performance. This energy efficiency is advantageous for cloud providers and companies developing edge devices where power consumption is a concern.
The API efficiently handles both large and small batch sizes, offering developers flexibility in optimizing inference workloads according to specific application needs, whether for real-time processing or batch operations.
Drawbacks
It should be noted that GroqCloud currently does not offer all models on its cloud platform, and there is no provision for uploading custom models to the API at this time. This limitation may impact certain use cases requiring specific or custom-trained model architectures.
Gradio-Powered Applications
Gradio excels in its ability to enable the rapid and straightforward creation of interactive machine-learning demos and interfaces without the need for extensive web development or user interface design expertise. Its simplicity, flexibility, and user-friendly characteristics make it an outstanding tool for machine learning developers and researchers. Similar to Streamlit, Gradio allows us to choose the most suitable platform depending on the specific requirements of the application.
This video demonstrates the Speech2Speech Machine Translator interface on Gradio.
3790 El Camino Real #1201 Palo Alto CA 94306